Building a Spark distributed cluster |
SuperMap iServer provides a built-in Spark installation package. You also can build Spark distributed cluster on other computer. Note: The version of Spark should be consistent with the one in iServer, and the version of Hadoop should be a corresponding version. Currently the Spark version in iServer is spark-2.1.0-bin-hadoop2.7, so the Hadoop version should be 2.7.x. It will introduce how to build Spark cluster on a Linux computer as follows.
The sample will use VMware Workstation 11.0.0 build-2305329, and create 3 Ubuntu 14.04 VM with the same configuration, one of them is the Master node, and the others are Worker nodes. The three VMs are named as Master, Worker1, Worker2 (the names are the VM names, not the host name of the system in the VM), and their IPs are Master: 192.168.177.136, Worker1: 192.168.177.135, Worker2: 192.168.177.137.
It needs Java environment (the JDK download like is http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html#javasejdk, it's suggested to use JDK 8 or above), and to configure SSH and Spark (the download link is: http://spark.apache.org/downloads.html).
Here it uses:
The following will take the Master node as an example, which is the same with the Worker node.
All operations should use root user. You can use the following command to convert a common user to the root user:
sudo -i
Input the current user password again.
It needs the following ports:
Check whether the port is available as follows:
ufw status
Enable the port as follows:
ufw allow [port]
[port] is the open port number. E.g.:
ufw allow 8080
Here it saves the downloaded JDK package in /home/supermap/
Extract the JDK package
tar -xvf jdk-8u111-linux-x64.tar.gz
Create java folder in /usr/lib/:
mkdir /usr/lib/java
Copy or move the extracted JDK files to /usr/lib/java, e.g.:
cp -r /home/supermap/jdk-8u111-linux-x64/ /usr/lib/java
Open the environment variable configuration file:
vi ~/.bashrc
Press i to edit. Write the following codes in the end of the configuration file:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_111
export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}/jre/lib
export PATH=${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin:$PATH
Press esc to exit the editing mode, input :wq to save an exit the editing.
Activate the new configuration with the following command:
source ~/.bashrc
Check whether Java is installed successfully:
java -version
If it shows the installed Java" version information, it means it is successful.
Spark uses SSH for communication. Input the following command to install SSH when the external Internet is connected.
apt-get install open-ssh
When it uses internal network, it needs a file transfer tool such as XManager to transfer the downloaded .deb package to the VM to install, and the installation command is as follows:
dpkg -i /home/supermap/openssh-server_6.6p1-2ubuntu1_amd64.deb
Check whether SSH is installed successfully:
ps -e|grep ssh
If it shows the following information it means it is successful
It can set SSH non-code validation to realize the communication without passwords.
Generate a private keygen, where " means two ':
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Then it will generate two files: id_dsa and id_dsa.pub in /root/.ssh, where id_dsa is private, id_dsa.pub is public.
It needs to append id_dsa.pub to authorized_keys which is used to save all public keygen contents to allow accessing ssh client with current user role:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Check whether it can access SSH without password:
ssh localhost
Input yes to log in. After completed, input exit to exit localhost. It doesn't need a password for the next log-in.
Configure in the Worker node with the same steps.
To realize the communication without password between the nodes, it needs to copy the public key in the Worker node to Master, then append them to authorized_keys in Master.
In Worker1, copy the public key to Master:
scp id_dsa.pub root@192.168.177.136:/root/.ssh/id_dsa.pub.Worker1
In Worker2, copy the public key to Master:
scp id_dsa.pub root@192.168.177.136:/root/.ssh/id_dsa.pub.Worker2
Append the public key to authorized_keys in Master:
cat ~/.ssh/id_dsa.pub.Worker1 >> ~/.ssh/authorized_keys
~/.ssh/id_dsa.pub.Worker2 >> ~/.ssh/authorized_keys
In Master copy authorized_keys to two Worker nodes:
scp ~/.ssh/authorized_keys root@192.168.177.135:/root/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@192.168.177.136:/root/.ssh/authorized_keys
Then it will not need a password between the Master and the Worker node.
Download Spark and save it in /home/supermap/
Extract the Spark package:
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz
Create Spark folder in /usr/local/:
mkdir /usr/local/spark
Copy the extracted spark-2.1.0-bin-hadoop2.7 to /usr/local/spark:
cp -r /home/supermap/spark-2.1.0-bin-hadoop2.7.tgz/ /usr/local/spark
Configure Spark environment variable
Open the environment variable configuration file with the following command:
vi ~/.bashrc
Press i to edit. Write the following codes in the end of the configuration file:
export SPARK_HOME=/usr/local/spark/spark-2.1.0-bin-hadoop2.7
Add the bin directory to PATH, then it will be like:
export PATH=${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin:${SPARK_HOME}/bin:$PATH
Press esc to exit the editing mode, input :wq to save an exit the editing.
Activate the new configuration with the following command:
source ~/.bashrc
Configure the Master node for Spark
Go to the Spark configuration file directory:
cd /usr/local/spark/spark-2.1.0-bin-hadoop2.7/conf
There is no spark-env.sh file in current directory, it needs to modify spark-env.sh.template to spark-env.sh. Copy spark-env.sh.template to spark-env.sh with the following command:
cp spark-env.sh.template spark-env.sh
Open spark-env.sh
vi spark-env.sh
Press i to edit, add the following codes in the end of the file
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
export JAVA_HOME=$SPARK_HOME/../jre
export UGO_HOME=$SPARK_HOME/../objectsjava
export PATH=$JAVA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$UGO_HOME/bin:$LD_LIBRARY_PATH
export SPARK_CLASS_PATH=$SPARK_HOME/../../webapps/iserver/WEB-INF/iobjects-spark/com.supermap.bdt.core-9.0.0-14819.jar
Where:
In addition, you can set the port of the Master node, worker node, Master Web UI, etc.
If you want to customize the port, please refer to check whether the firewall has opened the port.
Press esc to exit the editing mode, input :wq to save an exit the editing.
Modify host name
Please refer to Modify host name.
Configure the Worker node for Spark
Each Worker node should be configured in the slaves file. The slaves file is not provided in Spark installation package directly, but slaves.template is provided in the configuration file directory, so the way how to generate the slaves file is the same with spark-env.sh:
cp slaves.template slaves
Open the slaves file.
vi slaves
Delete the default node “localhost”, input the host name of each node in Spark cluster:
sparkmaster
sparkworker1
sparkworker2
The configuration contents of the three nodes are the same. Save and exit the editing.
Start the Master node
Execute the following commands in the computer the Master node is on:
cd /usr/local/spark/spark-2.1.0-bin-hadoop2.7/sbin
./start-master.sh
Start the Worker node
Execute the following commands in the computer the Worker node is on:
cd /usr/local/spark/spark-2.1.0-bin-hadoop2.7/sbin
./start-slave.sh --webui-port 8081 spark://sparkmaster:7077
Where:
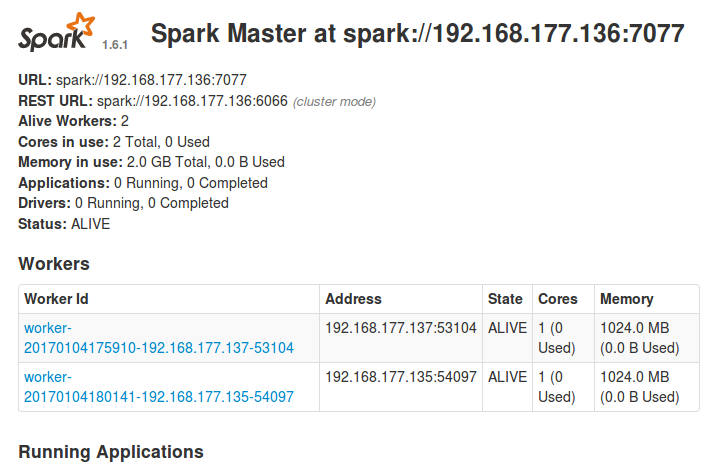
After starting, enter http: // sparkmaster: 8080 in the browser to view the cluster.